
Discover how in-context learning empowers large language models like GPT-3 to learn new tasks during inference without altering their model parameters.
Table of Contents
- Working Mechanism of In-Context Learning
- Bayesian Inference Framework for In-Context Learning
- Approaches: Few-Shot, One-Shot & Zero-Shot Learning
- Prompt Engineering Strategies
1. Working Mechanism of In-Context Learning
In-context learning (ICL) empowers large language models (LLMs) such as GPT-3 to learn new tasks during inference without altering their model parameters. This means that these LLMs can utilize task demonstrations integrated into prompts in natural language format for on-the-fly learning. Conventional machine learning models that rely solely on input-output pairs they were trained on. ICL enables LLMs to generalize from examples using the prompt as a semantic prior guiding their train of thought and output. Therefore, by leveraging ICL, LLMs can adapt quickly to new tasks without requiring extensive retraining or modifications to their existing structure or parameters. Learn more about in-context learning

Moreover, the integration of in-context learning with large language models is closely linked with prompt engineering strategies. Prompt engineering involves crafting effective prompts that encapsulate task specifications and guide the model towards generating desired output. By utilizing well-crafted prompts tailored for specific tasks, LLMs can swiftly comprehend complex instructions and generate accurate responses.
Bayesian inference frameworks for in-context learning suggests incorporating prior knowledge through prompts facilitates efficient decision-making processes. This is possible by allowing these systems to reason probabilistically about various inputs they encounter during inference. This connection amplifies their capacity for nuanced reasoning across diverse domains.
2. Bayesian Inference Framework for In-Context Learning
In-context learning occurs when LLMs, dynamically adjust their behavior based on the context of input-output examples. The Stanford AI Lab proposed a Bayesian inference framework to elucidate this process. This framework suggests that in-context learning is an emergent behavior. Meaning it arises from the interaction of various components within the model without explicit optimization of parameters. Instead of fine-tuning specific weights or biases, the model conditions its responses on prior knowledge acquired during pre-training. So, rather than adjusting internal configurations for each new task encountered, LLMs leverage their extensive pre-training data to perform tasks. Consequently, this approach enhances adaptability and generalization capabilities across various domains with minimal additional training requirements.
This Bayesian inference framework also complements prompt engineering strategies used to guide LLMs’ behavior toward desired outcomes. This is due to relevant prompts or examples tailored to specific tasks or queries. Such as few-shot or zero-shot learning scenarios helps direct the model’s attention towards pertinent information while leveraging its contextual understanding.
3. Approaches: Few-Shot, One-Shot & Zero-Shot Learning
In-context learning encompasses various approaches that enable large language models to adapt to new tasks with minimal training data. One such approach is Few-Shot Learning, where the model is provided with just a few examples related to the task at hand. This allows the model to understand how best to perform the given task by leveraging its pre-existing knowledge base. Example: “Simplify these sentences: ‘The cat, which was brown and white, sat on the mat.’. Simplified: ‘The brown and white cat sat on the mat.’. ‘The sun set at 8 PM, marking the end of the day.’. Simplified: ‘The sun set at 8 PM, ending the day.’. Now simplify: ‘The bakery, known for its delicious bread, opens at 9 AM.'”
On the other hand, One-Shot Learning takes adaptation a step further by requiring only one example for the model to learn from. This approach enables rapid adaptation towards new tasks or concepts based on just a single piece of information. For example, if an AI assistant needs to learn a new skill after being shown how it’s done just once, it can utilize one-shot learning methods for quick assimilation and application of that knowledge. Example: “Correction: ‘Their going to the park.’. Correct Sentence: ‘They’re going to the park.’. Now correct this: ‘I can’t hardly believe it.'”
Zero-Shot Learning represents another notable approach within in-context learning that doesn’t rely on labeled training data but instead leverages pre-trained knowledge exclusively. In this method, models are expected to generalize their understanding across diverse tasks without any specific examples during training. Example: “Translate the following sentence into French: ‘How are you today?'”
Chain-of-thought (COT) Prompting is an innovative technique that helps bolster the reasoning capabilities of large language models (LLMs). Integrating intermediate reasoning steps enhances the model’s ability to engage in complex reasoning tasks effectively. This approach becomes even more powerful when combined with few-shot prompting, allowing LLMs to grasp intricate concepts and solve intricate problems more adeptly. This advancement holds great potential for elevating the performance of language models in various areas, improving their overall reasoning proficiency.
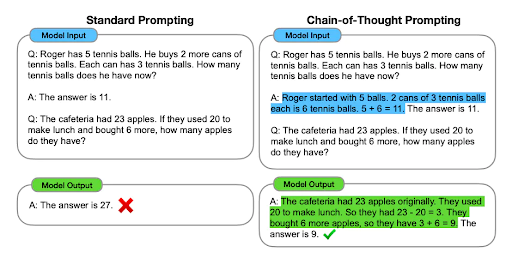
4. Prompt Engineering Strategies
In-context learning leverages the power of large language models like GPT-3 by enabling them to understand and respond based on the provided context. This approach allows these models to generate more accurate and relevant outputs for various tasks. Prompt engineering plays a crucial role in enhancing in-context learning by crafting precise instructions or queries that guide the LLMs toward producing desired results. For instance, when seeking information about renewable energy sources from an LLM, a well-crafted prompt can ensure that the model provides comprehensive and reliable data, thus showcasing its practical application within specific domains.
Large language models often rely on prompt engineering techniques to harness their full potential effectively. However, due to their complexity, these prompts can be sensitive to even minor alterations leading to significant variations in outputs. Thus, it becomes essential for developers and researchers working with LLMs to employ robust prompt-engineering strategies that account for potential brittleness while ensuring consistent performance across different scenarios.
To mitigate the challenges associated with prompt engineering’s brittleness within LLMs, several strategies have been proposed. One such strategy involves leveraging human feedback loops where users interactively refine prompts based on model responses until satisfactory outcomes are achieved consistently. Additionally, fine-tuning prompts using Bayesian optimization techniques could aid in optimizing their effectiveness while reducing sensitivity towards small modifications or noise inputted into LMMs.
Considering the potential of in-context learning and its integration with Bayesian inference frameworks, it’s essential for researchers and developers to further explore practical applications across diverse domains. Emphasizing robust prompt engineering strategies while mitigating brittleness within LLMs can lead to more consistent and reliable performance. Furthermore, investigating how few-shot, one-shot, and zero-shot learning approaches can be tailored for specific use cases will contribute to harnessing the full adaptability of LLMs. This cohesive approach could pave the way for enhanced human-machine interactions and advanced problem-solving capabilities.