

Exploring the Frontiers of AI Reasoning with Zero-shot Chain of Thought. If you provide the LLMs with well-crafted prompts, you can steer them toward answering questions that require reasoning and step-by-step thinking. Are you curious about how Large Language Models like GPT-3 excel at zero-shot reasoning and multi-step System-2 tasks?
Table of Contents
- System-1 and System-2 Tasks in LLMs
- Introduction to Chain of Thought (CoT)
- Zero-Shot Chain Of thought (Zero-shot-CoT)
- Two-stage Prompting In Zero-shot-CoT
1. System-1 and System-2 Tasks in LLMs
Large Language Models (LLMs) like GPT-3 have revolutionized Natural Language Processing by showcasing exceptional proficiency in understanding human language. Their remarkable abilities enable them to excel at few-shot and zero-shot learning, empowering them to adapt to various tasks without specific training or extensive examples. This adaptability is pivotal as it allows LLMs to swiftly generalize from minimal instances or task descriptions. For example, they can comprehend and respond sensibly even when presented with entirely new prompts that are not part of their training data.
While LLMs excel at intuitive single-step System-1 tasks, such as language translation or text completion. These tasks rely on quick pattern recognition and are well-suited to LLM capabilities. However, when it comes to complex multi-step reasoning required for System-2 tasks like critical thinking or logical inference, LLMs often face challenges due to their limited contextual understanding and inability to connect multiple pieces of information coherently. As a result, they may struggle with tasks that involve deeper analysis or require sequential logic.
To address this limitation, techniques such as Chain of Thought prompting have been developed. This approach guides LLMs through logical steps by breaking down complex problems into simpler sub-steps. For instance, in Zero-shot reasoning where an AI model is asked questions that it has not been explicitly trained on, Chain of Thought prompting helps the model reason through intermediate steps to arrive at accurate answers using its existing knowledge base without explicit training for those specific questions. By providing structured guidance through interconnected reasoning steps, this technique enables LLMs to navigate multi-step processes more effectively and improve their performance on System-2 tasks.
By integrating Chain of Thought prompting into Zero-shot-CoT settings, Large Language Models can expand their problem-solving capabilities beyond single-step intuition-based tasks towards more intricate multi-step reasoning scenarios. This integration allows them to apply sequential logic while drawing upon pre-existing knowledge base which significantly enhances their ability for zero-shot reasoning across various domains.
2. Introduction to Chain of Thought (CoT)
Chain of Thought prompting is an integral feature in LLMs that enables them to maintain a better reasoning across multiple prompts or queries, leading to coherent responses throughout a conversation or sequence of questions. Essentially helps AI to ‘think’ more like humans by breaking down problems into a simpler steps.
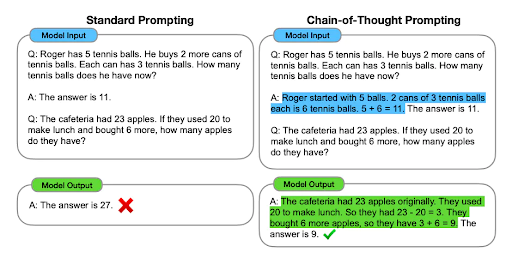
For instance, let’s consider a basic problem: “If you have 3 apples and someone gives you 2 more, how many apples do you have?”. A CoT approach would involve the model first recognizing that you start with 3 apples, then acknowledging that you receive 2 additional apples, and finally adding these quantities step by step: 3 apples + 2 apples = 5 apples. This process mirrors how a human might solve the problem, emphasizing logical progression and clarity.
The beauty of CoT lies in its simplicity and versatility. It’s not just limited to arithmetic problems but extends to a variety of domains like commonsense reasoning. For example where the AI might be asked to deduce why it’s a bad idea to microwave a metal spoon. Here, the AI would use CoT to reason that metals conduct electricity and that microwaves use electromagnetic waves. Furthermore leading to the conclusion that microwaving a metal spoon could cause sparks or a fire. This methodical, step-by-step processing is what makes CoT an invaluable tool, helping machines to reason and understand more effectively.
The success of Large Language Models lies not only in their vast capacity but also in their sophisticated architecture that facilitates complex reasoning processes while maintaining contextual coherence within diverse conversational contexts. Therefore these models play a crucial role in advancing Natural Language Processing capabilities by providing efficient solutions for System-1 tasks involving short-term memory-based inference as well as System-2 tasks requiring long-term memory-based comprehension.
3. Zero-Shot Chain Of thought (Zero-Shot-CoT)
Executing multi-hop reasoning across various tasks using a single prompt has been challenging until the introduction of the Zero-Shot Chain Of Thought (Zero-Shot CoT) strategy. This novel prompting strategy that differs significantly from both standard CoT and traditional template prompting. It is inherently task-agnostic and elicits multi-hop reasoning across a range of tasks using a single prompt. The core principle involves using a simple prompt like “Let’s think step by step” to extract step-by-step reasoning without requiring specific examples for each task. This approach simplifies the prompting process and broadens the scope of tasks that LLMs can handle effectively.

Chain of Thought prompting involves guiding the model through a sequence of prompts where each step builds upon the previous one, leading to deeper understanding and more comprehensive responses. In traditional settings, such as Few-shot-CoT, this process requires tailored prompts for specific types of tasks or domains, limiting its applicability across different scenarios. However, with Zero-shot-CoT, LLMs can seamlessly engage in multi-hop reasoning across various tasks using a single prompt without needing predefined examples for each task. This simplifies the prompting process while expanding the potential applications of large language models.
Zero-Shot-CoT successfully improve the reasoning without any input overhead how ever, complex reasoning process that can be hard to parse for a specific answer. The language model, while effectively breaking down the problem, generates extensive text. This makes extracting a concise answer challenging. A follow up prompt approach addresses this by honing in on the detailed response to distill a clear, direct answer. It acts like a filter, transforming the model’s elaborate explanation into a precise conclusion, thus ensuring the final output is both accurate and easily understandable.
The concept of two-stage prompting in Zero-shot-CoT wherein an initial prompt sets up a general context followed by subsequent questions that guide the model’s chain of thought towards nuanced reasoning on diverse topics. By enabling multi-hop reasoning without explicit task-specific examples, Zero-shot-CoT streamlines the interaction between users and large language models while enhancing their ability to comprehend complex inquiries spanning different domains.
4. Two-stage Prompting In Zero-Shot-CoT
This version of Zero-shot-CoT involves a two-stage prompting process. The first stage focuses on reasoning extraction, where the model is prompted to think through the problem step by step. The second stage is answer extraction, where the model consolidates its reasoning to provide a final answer. This dual-prompt strategy enhances the LLM’s ability to not only reason through a problem but also to articulate a clear, concise answer.
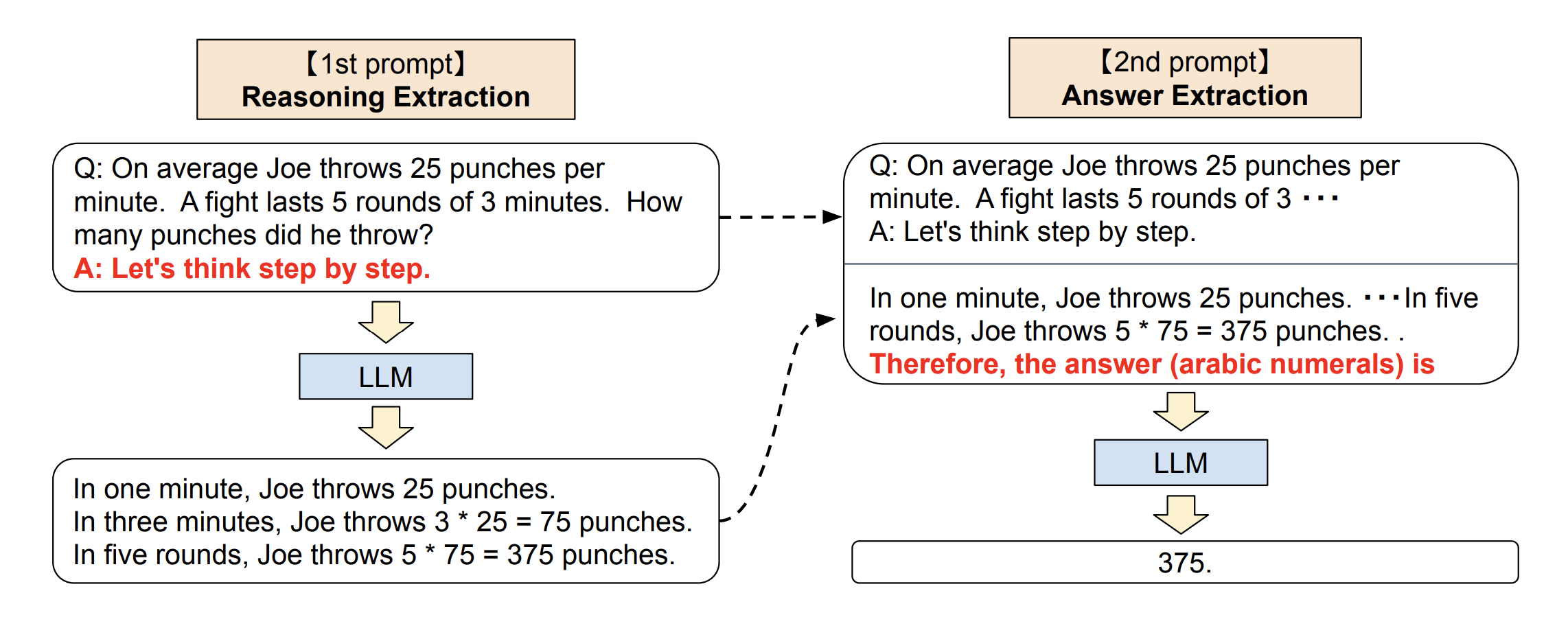
In Zero-Shot CoT’s first stage, the large language model engages in intricate thinking processes akin to System-2 tasks by breaking down complex prompts into smaller steps or subtasks. During this phase, it meticulously extracts relevant information from the input prompt to build a coherent chain of thoughts leading towards an informed conclusion. Once this reasoning process is completed, we move into the second stage which entails extracting answers from these consolidated chains of thought. This method enables LLMs to articulate their responses with improved clarity and precision by showcasing how they arrived at specific conclusions through logical chains.
This twofold approach not only demonstrates large language models’ prowess in zero-shot reasoning but also showcases their ability to emulate human-like cognitive processes while tackling complex queries. By incorporating distinct stages focusing on both meticulous reasoning extraction and subsequent answer consolidation within Zero-shot-CoT, these models exhibit enhanced comprehension abilities similar to those utilized during System-1 tasks like question answering or completion prompts.
To harness these advancements effectively, exploring further research on refining multi-step reasoning processes within LLMs is essential. Understanding how to optimize their performance on System-2 tasks through advanced techniques like Zero-shot-CoT will be pivotal for leveraging their full potential in diverse applications.